Rで『身近な統計(’12)』 – 第7章 その1
少し飛んで、第7章です。
離散型確率変数の期待値・分散・標準偏差
forを使う
配列変数などに格納された値を、順に処理して、合計するには、for文などの繰り返しを使う方法があります。
- 7行目
length()は、オブジェクトの長さ(要素の数)を返す関数です。ベクトルの長さを調べて、繰り返しの回数にします。 - 9行目、13行目
Rでは、存在しない変数を参照するとエラーになりますので、ここで、期待値、分散に使う変数に0を代入して準備しています。 - 10行目、14行目
iを1〜lまで順に変化させながら、後に続く文を繰り返します。文が複数になる場合は、繰り返したい文を{}で囲みますが、今回は続く文が1文なので、囲んでいません(もちろん、囲んでも構いませんし、意図的に囲む場合もあります)。短い場合は”for(i in 1:l) e <- e + (m[i] * p[i])” のように1行に記述することも多いです。 - 17行目
sqrt()は平方根を求める関数です。 - 20行目以下
cat()は、画面やファイルに文字列を出力します。cat()は改行をしてくれないので、”\n“を付けて改行しています。print()もありますが、それなりの形で出力するためには準備が必要なため、今回はcat()にしました。
forを使わない
一応、これで計算できるのですが、Rでは、一度の計算で、ベクトルの個々の要素を評価したり、計算を繰り返したりすることが、自動的に行われるため、簡単な計算を行うのに、繰り返しなどの制御文はあまり使いません。forを使わずに書いてみます。
- 7行目、8行目:
sum()は、ベクトルの要素の和を求める関数です。
forを使っている部分を、ひとつの代入文で書くことができて、かなりすっきりしました。
関数化・サブルーチン化する
教科書では2通りの賞金配分について計算をしているので、同じ計算を2回書かなくてはなりません。ここで、繰り返しを使うのもひとつの方法ですが、何回も使うものは、関数化、サブルーチン化してしまった方が楽ですし、使い回しもできます。
3行目〜8行目が期待値などを求める計算を、10行目〜17行目が結果の出力を、それぞれ関数化・サブルーチン化したものです。計算部分と出力部分をひとまとめにしても良かったのですが、個人的な好みと、説明のために、分けて書きました。身近な統計のためだけに作ったので、名前はfunc_NNhogeですが、実際に定義して利用する場合は、どのような処理をするのか、どのような値を返すのかがわかるような名前を付けましょう。
- 3行目〜8行目
ここでは計算する関数を定義しています。3行目の”func_07“が定義する関数名です。これに”<- function(...) {...}“として、関数の中身・本体を入れるイメージです。
function(x, p)のx, pは仮引数(かりひきすう)です。関数に引き渡される値を引数(ひきすう)と呼びますが、特に呼び出される関数側で値が引き渡される変数を仮引数といいます。
それに続く{...}が、実際の処理を定義している箇所です。forなどと同様に1文だけなら、{}で囲む必要はありません。
この中で使われている変数は、仮引数も含めて、この関数の中でのみ有効で、同じ名前であっても、呼出元や他の関数に影響を与えません。つまり、この関数の変数xに何を代入しても、この関数の外のxや、他の関数のxの値は変わりません。また、呼び出されるごとに、環境(変数など)が用意されるため、前回の呼出に影響されることや、次回の呼出に影響することはありません。 - 7行目
return()で、呼出元に処理の結果を返します。()の中の値が、関数の戻り値/返値(かえりち/へんち)になります。return()を書かなくても、最期に計算された値が戻り値になりますが、関数として使用する場合は明確に示すべきです。また、ruturn()が実行されると、その後の処理は行われません。ここでは、リストで計算結果を返しています。 - 10行目〜18行目
ここでは計算をして、出力をする関数を定義しています。10行目と11行目にx, pが使われています。10行目のx, pはfunc_07prnの仮引数ですが、11行目のx, pは、func_07の実引数です。実引数とは呼び出す側で実際に使用される引数をいいます。仮引数は変数でしたが、実引数は、変数でも値でも構いません。ここに書いてある値が、関数の仮引数にコピーされて、関数に引き渡されます。呼出元でも、計算結果を利用できるように、17行目で値を返しています。 - 20行目〜22行目
作った関数をつかって、期待値、分散、標準偏差を表示させます。
作った関数は、次のジャンボ宝くじ当せん金の期待値でも使えるので、関数の部分だけを取り出し、ファイル名を”chapter07_func.R“として、作業ディレクトリに保存しました。
ジャンボ宝くじ当せん金の期待値
付属のCDに保存されているデータを使いますが、当せん金額が…文字列ですね…こういうテーブルの作り方は、データの二次利用がしにくいので嫌われます。
Excelファイルから直接読み込むのか、CSV形式に変換して読み込むのか…そうだ、クリップボード経由でデータを読み込んでみよう!
当せん金の文字列を数値に直して、コピーします。(元データは残したかったので、値でコピーしてからなおしました。)
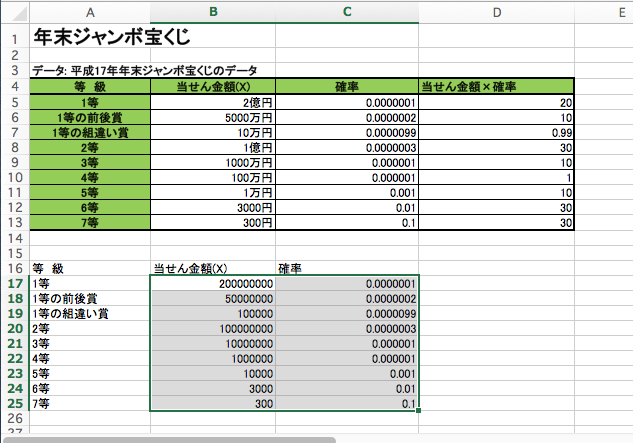
そして、読み込み…
- Windwosの場合
> j <- read.table("clipboard", header = FALSE) - Macの場合
> j <- read.table(pipe("pbpaste"), header = FALSE)
これで、変数jにテーブルが読み込まれました。変数名は何でも良かったのですが、年末ジャンボなので…。
一応、内容を確認しましょう。
> j
V1 V2
1 200000000 1.0e-07
2 50000000 2.0e-07
3 100000 9.9e-06
4 100000000 3.0e-07
5 10000000 1.0e-06
6 1000000 1.0e-06
7 10000 1.0e-03
8 3000 1.0e-02
9 300 1.0e-01列の名前が気に入らない(見ても何のデータなのか、わからないので)変えましょう。
> names(j) <- c("prize_money", "probability") # j の V1, V2を書き換えます。
> j
prize_money probability
1 200000000 1.0e-07
2 50000000 2.0e-07
3 100000 9.9e-06
4 100000000 3.0e-07
5 10000000 1.0e-06
6 1000000 1.0e-06
7 10000 1.0e-03
8 3000 1.0e-02
9 300 1.0e-01
names()を使うと、名前を参照したり、書き換えたりできます。
そして、一端、ファイルに出力しておきましょう。
> write.csv(j, "jumbo.csv", row.names = FALSE)j(の内容)を”jumbo.csv“というファイル名で、現在の作業ディレクトリへ、行の名前(番号)なしrow.names = FALSEで保存します。
そして、こんなのはどうでしょう。
- 2行目
保存しておいた自作の関数のファイルを読み込み、実行(関数を定義)します。 - 3行目
保存しておいたデータを読み込みます。(プログラムの実行が終わった後で構いませんので、jの内容を確認しておいて下さい。) - 4行目
関数を呼び出して計算させます。
…いかがでしょうか。
